
N8N과 Playwright를 연동하면 RSS 피드나 웹 크롤링 자동화를 강력하게 구현할 수 있어요. 이 글에서는 Playwright를 Server Mode로 실행하고, FastAPI로 API 서버를 구축한 다음, N8N에서 RSS 피드의 URL을 크롤링하는 전체 과정을 다뤄요.
📑 목차
전체 구조 및 동작 방식
우리가 구축할 시스템의 전체 흐름이에요. 모든 서비스는 Docker에 올라가 있고, 공통된 Network를 사용하고 있어요.
서비스는 Docker Compose로 동작중이에요.

| 단계 | 설명 (초보자 언어) |
|---|---|
| 1. URL 스크래핑 요청 | N8N에서 FastAPI로 스크래핑하고 싶은 URL을 포함해서 요청을 보내요. |
| 2. Playwright 요청 전달 | FastAPI는 N8N에서 받은 요청을 보고 Playwright를 조작해 해당 URL로 접속해요. |
| 3. HTML Content 추출 | URL에 접속되었다면 FastAPI는 다시 Playwright를 조작해 해당 URL HTML의 Content를 추출해요. |
| 4. HTML 정보 n8n 전달 | 추출한 Content를 N8N으로 Response 해요. |
1단계: Playwright Server (Docker) 구축
Playwright를 원격 제어 서버로 실행해서 Docker 환경에서 안정적으로 브라우저를 관리할 거예요. 다른 서비스(FastAPI, N8N)가 네트워크를 통해 제어할 수 있게 되는 거죠.
Docker Compose로 Playwright Server 실행
docker-compose.yml 파일은 여러 개의 Docker 컨테이너를 한 번에 실행하고 관리하게 해주는 '설계도'예요. FastAPI와 Playwright를 동시에 띄울 거예요.
# Docker Compose 파일 버전
version: '3.8'
# 'services'는 실행할 컨테이너들의 목록이에요.
services:
# 1. Playwright 서비스 (이름: playwright)
playwright:
# 사용할 Docker 이미지 (MS 공식 Playwright 이미지예요)
image: mcr.microsoft.com/playwright:v1.56.0-noble
container_name: playwright-server
# [핵심] 컨테이너가 실행될 때 내릴 명령어예요.
# npx playwright@1.56.0 run-server: Playwright를 제어 가능한 서버 모드로 실행
# --host 0.0.0.0: 컨테이너 외부(다른 컨테이너)에서 접근 허용
# --port 3000: 3000번 포트로 서버를 엶
command: npx -y playwright@1.56.0 run-server --host 0.0.0.0 --port 3000
ports:
# "외부:내부" - 내 PC(Host)의 3000번 포트를 컨테이너의 3000번 포트로 연결
- "3000:3000"
# Chromium이 제대로 동작하려면 공유 메모리(/dev/shm)가 충분해야 해요.
shm_size: 2gb
# 'app-network'라는 가상 네트워크에 이 컨테이너를 연결할 거예요.
networks:
- app-network
# Docker Compose의 depends_on은 Docker의 시작 순서만 보장해줘요.
# Playwright 컨테이너가 동작해도 3000번 포트로 리스닝하기까지 잠시의 딜레이가 있어요.
# 해당 딜레이로 인해 fastapi 서비스에 문제가 발생할 수 있으니 healthcheck를 통해 방지해요.
healthcheck:
test: curl -f http://localhost:3000 || exit 1
interval: 5s
timeout: 3s
retries: 20
start_period: 20s
# 2. FastAPI 서비스 (이름: fastapi)
fastapi:
# 'build: ./fastapi'는 'fastapi' 폴더에 있는 Dockerfile로 이미지를 만들라는 뜻이에요.
build: ./fastapi
container_name: fastapi-server
ports:
# 내 PC의 8000번 포트를 컨테이너의 8000번 포트로 연결해요.
# N8N에서 http://localhost:8000 으로 접근하기 위해 필요해요.
- "8000:8000"
# [핵심] 'playwright' 서비스가 먼저 실행된 후에 'fastapi'를 실행해요.
depends_on:
- playwright
environment:
# FastAPI 코드(main.py)에서 사용할 환경 변수 설정이에요.
# [중요!] ws://playwright:3000
# 'localhost'가 아닌 'playwright'예요. Docker가 'playwright'라는 이름을
# 같은 네트워크의 'playwright-server' 컨테이너 IP로 자동 변환해줘요.
- PLAYWRIGHT_SERVER_URL=ws://playwright:3000
# Playwright와 동일한 'app-network'에 연결해요.
networks:
- app-network
# 사용할 Docker 가상 네트워크(연결망)를 정의해요.
networks:
app-network:
driver: bridge # Docker의 기본 네트워크 드라이버예요.🔍 Docker-compose.yml 핵심 요약
- services: playwright와 fastapi라는 두 개의 독립된 서비스를 정의해요.
- command: playwright 서비스가 run-server 모드로 실행되도록 명령어를 지정해요.
- networks: 두 서비스를 app-network라는 동일한 가상 네트워크에 연결해요.
- depends_on: playwright 서비스가 먼저 실행된 후에 fastapi 서비스가 실행되도록 순서를 보장해요.
- environment: fastapi 서비스가 playwright 서비스를 ws://playwright:3000이라는 주소로 찾을 수 있도록 환경 변수를 설정해요. Docker 네트워크 덕분에 localhost가 아닌 서비스 이름(playwright)으로 통신할 수 있어요.
- shm_size: Chromium(Chrome)은 실행 시 많은 공유 메모리를 사용해요. 이 설정을 안 해주면 브라우저가 예기치 않게 종료될 수 있어요.
저는 N8N을 이미 Docker로 구동 중이기에Network만 맞춰서 동작시켰어요.
2단계: FastAPI 서버 구축
FastAPI는 N8N과 Playwright Server를 연결하는 '중간 관리자'예요. N8N에서 들어온 간단한 HTTP 요청(URL)을 받아, 복잡한 Playwright 제어 로직(Python)을 대신 실행해 줘요.
프로젝트 구조
docker-compose.yml이 있는 폴더에 fastapi라는 하위 폴더를 만들어요.
project/
├── docker-compose.yml (1단계에서 만듦)
└── fastapi/ (새로 만듦)
├── Dockerfile
├── requirements.txt
└── main.py
FastAPI Dockerfile
fastapi 컨테이너를 만드는 '레시피'예요.
# 1. 기본 이미지 선택 (가벼운 Python 3.11 버전)
FROM python:3.11-slim
# 2. 컨테이너 내부의 작업 폴더를 '/app'으로 설정해요.
WORKDIR /app
# 3. 'requirements.txt' 파일을 컨테이너의 /app 폴더로 복사해요.
COPY requirements.txt .
# 4. 복사한 'requirements.txt'를 이용해 Python 패키지를 설치해요.
RUN pip install --no-cache-dir -r requirements.txt
# 5. 현재 폴더(fastapi/)의 모든 파일(main.py 등)을 컨테이너의 /app 폴더로 복사해요.
COPY . .
# 6. 컨테이너가 실행될 때 수행할 기본 명령어예요.
# 'uvicorn'은 FastAPI를 실행하는 서버예요.
# 'main:app'은 'main.py' 파일 안의 'app' 객체를 실행하라는 의미예요.
# '--host 0.0.0.0': 컨테이너 외부에서의 접근을 허용해요. (필수)
# '--port 8000': 8000번 포트로 서버를 열어요.
CMD ["uvicorn", "main:app", "--host", "0.0.0.0", "--port", "8000"]https://fastapi.tiangolo.com/ko/
FastAPI
FastAPI framework, high performance, easy to learn, fast to code, ready for production
fastapi.tiangolo.com
필요한 Python 패키지
# 1. FastAPI: API 서버를 만들기 위한 핵심 프레임워크예요.
fastapi==0.121.1
# 2. Uvicorn: FastAPI를 실행시켜주는 ASGI 웹 서버예요.
uvicorn[standard]==0.38.0
# 3. Playwright: 브라우저를 제어하는 Python 라이브러리예요.
# [중요] 이 컨테이너는 Playwright '클라이언트' 역할만 해요.
# 실제 브라우저(Chromium 등)는 'playwright-server' 컨테이너에 있어요.
playwright==1.56.0
# 4. Pydantic: 데이터 유효성 검증 (N8N 요청이 URL 형식이 맞는지 등)을 해줘요.
pydantic==2.9.2FastAPI 메인 코드 (상세 주석)
가장 중요한 '중간 관리자'의 로직이에요.
from fastapi import FastAPI, HTTPException, status
from fastapi.middleware.cors import CORSMiddleware
from pydantic import BaseModel, HttpUrl, Field
# 비동기 Playwright와 브라우저 객체, 타임아웃 에러를 가져와요.
from playwright.async_api import async_playwright, Browser, TimeoutError as PlaywrightTimeout
# 'Optional'과 'Literal'만 필요해요.
from typing import Literal, Optional
# 'lifespan' 구현용
from contextlib import asynccontextmanager
import os
import logging
from datetime import datetime
# ==========================================
# 로깅 설정
# ==========================================
logging.basicConfig(
level=logging.INFO,
format='%(asctime)s - %(name)s - %(levelname)s - %(message)s'
)
logger = logging.getLogger(__name__)
# ==========================================
# 전역 변수 (브라우저 인스턴스)
# ==========================================
# FastAPI 서버가 실행되는 동안 브라우저 연결을 저장할 전역 변수예요.
browser: Optional[Browser] = None
# ==========================================
# Lifespan Context Manager (서버 시작/종료 관리)
# ==========================================
@asynccontextmanager
async def lifespan(app: FastAPI):
"""
FastAPI 애플리케이션의 전체 생명주기를 관리해요.
'yield' 이전 코드는 서버 시작 시 *단 한 번* 실행돼요.
'yield' 이후 코드는 서버 종료 시 *단 한 번* 실행돼요.
"""
global browser
playwright_url = os.getenv("PLAYWRIGHT_SERVER_URL", "ws://playwright:3000")
playwright_instance = None
# --- 서버 시작 시 실행되는 코드 ---
logger.info("🚀 FastAPI 서버 시작 중...")
logger.info(f"📡 Playwright Server에 연결 시도: {playwright_url}")
try:
# 1. Playwright 인스턴스 시작
playwright_instance = await async_playwright().start()
# 2. 원격 브라우저에 연결 (단 1회)
browser = await playwright_instance.chromium.connect(
playwright_url,
timeout=10000
)
logger.info("✅ Playwright 브라우저 연결 완료!")
logger.info("💡 이제 모든 요청이 이 브라우저를 재사용해요!")
# 3. FastAPI 서버가 요청을 받을 수 있도록 제어권을 넘겨줘요.
yield
except Exception as e:
logger.error(f"❌ Playwright 연결 실패: {str(e)}")
raise
finally:
# --- 서버 종료 시 실행되는 코드 ---
logger.info("🛑 FastAPI 서버 종료 중...")
# 4. 브라우저 연결을 닫아요.
if browser:
await browser.close()
logger.info("✅ Playwright 브라우저 연결 종료 완료")
# 5. Playwright 인스턴스를 완전히 종료해요. (메모리 누수 방지)
if playwright_instance:
await playwright_instance.stop()
logger.info("✅ Playwright 인스턴스 종료 완료")
# ==========================================
# FastAPI 애플리케이션 초기화
# ==========================================
app = FastAPI(
title="Playwright Scraper API",
description="lifespan으로 브라우저 연결을 재사용하여 단일 URL 크롤링 제공",
version="2.0.0",
lifespan=lifespan # ← FastAPI에 위에서 만든 lifespan 함수를 등록해요.
)
# CORS 설정 (모든 도메인 허용)
app.add_middleware(
CORSMiddleware,
allow_origins=["*"],
allow_credentials=True,
allow_methods=["*"],
allow_headers=["*"],
)
# ==========================================
# Pydantic 모델 정의 (데이터 유효성 검사)
# ==========================================
class ScrapeRequest(BaseModel):
"""
/scrape 엔드포인트의 요청 본문(body)을 정의해요.
"""
url: HttpUrl
wait_for: Literal["load", "domcontentloaded", "networkidle", "commit"] = "networkidle"
timeout: int = Field(
default=30000,
ge=1000, # 1초 이상
le=120000 # 120초 이하
)
screenshot: bool = Field(default=False)
block_resources: bool = Field(
default=False,
description="True로 설정 시, 속도 향상을 위해 이미지/CSS/폰트를 로드하지 않아요."
)
class ScrapeResponse(BaseModel):
"""성공적인 스크래핑 응답을 정의해요."""
url: str
html: str
title: str
success: bool
screenshot_base64: Optional[str] = None
scraped_at: str
response_time_ms: int
# ==========================================
# 헬스 체크 엔드포인트
# ==========================================
@app.get("/", tags=["Health"])
async def root():
"""단순히 API 서버가 살아있는지 확인해요."""
return {
"status": "ok",
"message": "Playwright Scraper API is running",
"version": "2.0.0"
}
@app.get("/health", tags=["Health"])
async def health_check():
"""
*실제로* Playwright 브라우저와 통신이 가능한지 확인해요.
"""
global browser
if browser is None:
return {
"status": "unhealthy",
"browser": "not connected",
"message": "브라우저가 연결되지 않았어요"
}
try:
# lifespan에서 연결된 브라우저로 새 페이지(탭)를 열었다 닫는 테스트를 수행해요.
test_page = await browser.new_page()
await test_page.close()
return {
"status": "healthy",
"browser": "connected",
"message": "브라우저가 정상적으로 연결되어 있어요",
"optimization": "lifespan enabled"
}
except Exception as e:
logger.error(f"헬스 체크 실패: {str(e)}")
return {
"status": "unhealthy",
"browser": "error",
"error": str(e)
}
# ==========================================
# 단일 크롤링 엔드포인트
# ==========================================
@app.post("/scrape", response_model=ScrapeResponse, tags=["Scraping"])
async def scrape_url(request: ScrapeRequest):
"""
단일 URL을 크롤링해요.
"""
global browser
# lifespan에서 브라우저 연결에 실패했거나, 아직 연결 중일 때
if browser is None:
raise HTTPException(
status_code=status.HTTP_503_SERVICE_UNAVAILABLE,
detail="브라우저가 연결되지 않았어요. 서버를 재시작해주세요."
)
start_time = datetime.now()
page = None # finally 블록에서 page 객체에 접근하기 위해 외부에 선언해요.
try:
logger.info(f"크롤링 시작: {request.url}")
# 1. 새 페이지(탭) 생성 (매우 빠른 작업)
# lifespan에서 연결한 전역 'browser' 변수를 사용해요.
page = await browser.new_page(
viewport={"width": 1920, "height": 1080}
)
# 2. 리소스 차단 (옵션)
if request.block_resources:
await page.route("**/*", lambda route: (
route.abort() if route.request.resource_type in ["image", "font", "stylesheet"]
else route.continue_()
))
logger.info("리소스 차단 활성화 (이미지/폰트/CSS)")
# 3. 페이지 기본 타임아웃 설정
page.set_default_timeout(request.timeout)
# 4. URL로 이동
await page.goto(
str(request.url),
wait_until=request.wait_for,
timeout=request.timeout
)
# 5. HTML과 제목 추출
html_content = await page.content()
page_title = await page.title()
# 6. 스크린샷 캡처 (옵션)
screenshot_base64 = None
if request.screenshot:
import base64
screenshot_bytes = await page.screenshot(
full_page=True,
type="png"
)
screenshot_base64 = base64.b64encode(screenshot_bytes).decode('utf-8')
response_time = int(
(datetime.now() - start_time).total_seconds() * 1000
)
logger.info(
f"✓ 크롤링 완료: {request.url} "
f"(제목: {page_title}, {response_time}ms)"
)
# 7. 성공 응답 반환
return ScrapeResponse(
url=str(request.url),
html=html_content,
title=page_title,
success=True,
screenshot_base64=screenshot_base64,
scraped_at=datetime.now().isoformat(),
response_time_ms=response_time
)
except PlaywrightTimeout as e:
logger.error(f"타임아웃: {request.url}")
raise HTTPException(
status_code=status.HTTP_504_GATEWAY_TIMEOUT,
detail={
"success": False,
"error": "페이지 로딩 타임아웃",
"error_type": "TimeoutError",
"url": str(request.url)
}
)
except Exception as e:
logger.error(f"크롤링 실패: {request.url} - {str(e)}")
raise HTTPException(
status_code=status.HTTP_500_INTERNAL_SERVER_ERROR,
detail={
"success": False,
"error": str(e),
"error_type": type(e).__name__,
"url": str(request.url)
}
)
finally:
# 8. 작업이 성공하든 실패하든, 페이지(탭)는 *반드시* 닫아야 해요.
# (브라우저(browser)는 닫지 않아요! 탭(page)만 닫아요!)
if page:
await page.close()
logger.debug(f"페이지 닫기 완료: {request.url}")
# ==========================================
# 서버 정보 엔드포인트
# ==========================================
@app.get("/info", tags=["Info"])
async def server_info():
"""현재 서버의 최적화 상태와 엔드포인트 정보를 보여줘요."""
global browser
return {
"version": "2.0.0",
"optimization": {
"lifespan": "enabled",
"browser_reuse": "enabled"
},
"browser_status": {
"connected": browser is not None,
"type": "chromium" if browser else None
},
"endpoints": {
"single": "/scrape",
"health": "/health"
}
}🔍 코드 핵심 요약
- global browser: lifespan에서 만든 전역 변수 browser를 /scrape 함수에서도 가져와 사용해요.
- await browser.new_page(): 요청이 올 때마다 브라우저를 새로 연결(connect)하는 대신, 이미 연결된 브라우저에서 새 탭(page)만 열기 때문에 매우 빨라요.
- finally: await page.close(): 가장 중요해요. 크롤링이 성공하든 실패하든, 사용한 탭(page)은 반드시 닫아야 해요. 탭을 닫지
FastAPI API 요약
우리가 main.py에서 만든 API 엔드포인트들을 요약하면 다음과 같아요.
| 메서드 | 경로 | 역할 | N8N에서 사용하는가? |
|---|---|---|---|
| GET | / |
서버가 살아있는지 확인하는 '헬스 체크'용이에요. | X (테스트용) |
| GET | /health |
Playwright 브라우저까지 연결되었는지 확인하는 '진짜' 헬스 체크예요. | X (테스트용) |
| POST | /scrape |
URL 1개를 받아서 크롤링하고 HTML을 반환해요. | O (핵심 기능) |
서버 실행하기
docker-compose.yml이 있는 폴더에서 아래 명령어를 실행해요.
# Docker Compose로 모든 서비스(fastapi, playwright)를 백그라운드(-d)로 실행해요.
docker compose up -d
# 로그(기록)를 실시간으로 확인해요 (-f).
docker compose logs -f
# FastAPI 서버만 재시작 (코드 수정 후 반영 시)해요.
docker compose restart fastapi
# 모든 서비스를 중지하고 컨테이너를 삭제해요.
docker compose down동작 확인
위 서버 실행하기에서 Docker Compose 서비스를 올린 뒤 서비스가 정상 동작하는지 curl로 직접 테스트해 보는 것이 좋아요.
FastAPI 헬스 체크
FastAPI 서버가 N8N의 요청을 받을 준비가 되었는지 확인해요. /health 엔드포인트를 호출해서 브라우저까지 잘 연결되었는지 확인하는 것이 더 정확해요.
# API 서버 및 브라우저 연결 상태 확인
curl http://localhost:8000/health정상 구동중일 경우 아래와 같은 응답을 볼 수 있어요.

단일 URL 크롤링 테스트
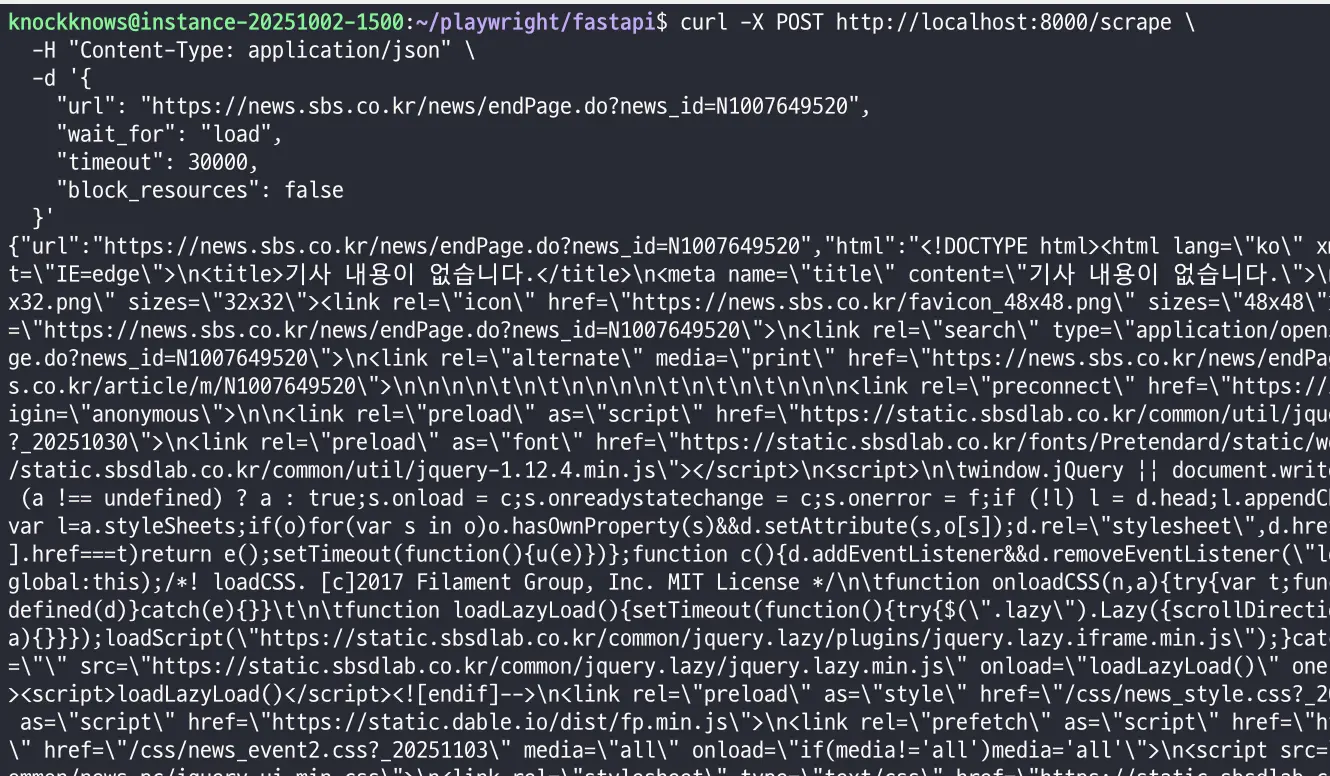
N8N을 설정하기 전에, FastAPI와 Playwright가 잘 연동되는지 curl 명령어로 직접 테스트해요.
# POST 요청으로 /scrape 엔드포인트에 크롤링 테스트
curl -X POST http://localhost:8000/scrape \
-H "Content-Type: application/json" \
-d '{
"url": "https://news.sbs.co.kr/news/endPage.do?news_id=N1007649520",
"wait_for": "load",
"timeout": 30000,
"block_resources": false
}'정상적으로 스크래핑되었을 경우 아래와 같은 응답을 볼 수 있어요.
3단계: N8N 워크플로우 설정
위 모든 테스트가 정상일 경우 이제 N8N에 연동해서 동작시켜 볼게요.
제가 만들 워크플로우는 RSS 피드에서 링크를 추출하고 요청을 정제한 다음, Playwright로 스크래핑 요청하는 거예요.
워크플로우 구조

1) Schedule Trigger + RSS Read 노드 설정
워크플로우의 시작은 'Schedule Trigger'와 'RSS Read'를 조합해서 사용하고 있어요. 'RSS Feed Trigger'로 대체해도 무방해요.
| 노드 | 설정 항목 | 값 | 설명 |
|---|---|---|---|
| Schedule Trigger | Trigger Interval | Every 15 Minutes (자유롭게) | "15분마다 이 워크플로우를 실행시켜줘"라는 명령이에요. |
| RSS Read | URL | (크롤링할 RSS 피드 주소) | 스케줄이 실행될 때마다 이 RSS 피드를 새로 읽어와요. |
https://docs.n8n.io/integrations/builtin/core-nodes/n8n-nodes-base.scheduletrigger/
Schedule Trigger node documentation | n8n Docs
Integrations Built-in nodes Core nodes Schedule Trigger Schedule Trigger node Use the Schedule Trigger node to run workflows at fixed intervals and times. This works in a similar way to the Cron software utility in Unix-like systems. You must activate the
docs.n8n.io
2) Code 노드 - URL 추출 및 요청 데이터 생성
RSS 노드에서 받은 데이터를 FastAPI 서버가 원하는 JSON 형식으로 '가공'하는 단계예요.
// N8N Code 노드는 'items'라는 배열을 반환(return)해야 해요.
// 'items' 배열의 각 요소(객체)는 다음 노드로 전달될 '데이터 항목(아이템)'이 돼요.
const items = [];
// $input.all() : 이전 노드(RSS Read)에서 들어온 *모든* 데이터 항목들을 배열로 가져와요.
for (const item of $input.all()) {
// item.json : N8N 데이터의 'json' 키 안에 실제 데이터가 들어있어요.
// RSS 피드의 'link' 필드에서 URL을 추출해요.
const url = item.json.link;
const title = item.json.title;
const pubDate = item.json.pubDate;
// URL이 유효한 경우(존재하고, http로 시작하는 경우)에만 처리해요.
if (url && url.startsWith('http')) {
// 'items' 배열에 새 객체를 추가(push)해요.
items.push({
json: {
// [중요] 다음 노드에서 사용하기 편하도록 데이터를 '가공'해요.
// 1. 원본 RSS 데이터 (나중에 참고하기 위해)
originalTitle: title,
originalPubDate: pubDate,
// 2. FastAPI 서버(/scrape)로 보낼 요청 본문(Body)
// (main.py의 ScrapeRequest 모델과 형식을 맞춰야 해요.)
scrapeRequest: {
url: url,
// "load"는 페이지 로딩이 빠르지만,
// JS 렌더링이 덜 끝난 페이지를 가져올 수 있어요.
// 문제가 생기면 "networkidle"로 변경해 보세요.
wait_for: "load",
timeout: 30000,
screenshot: false,
block_resources: false // 리소스 차단 안 함
}
}
});
}
}
// 가공된 아이템 배열을 다음 노드로 전달해요.
return items;
https://docs.n8n.io/integrations/builtin/core-nodes/n8n-nodes-base.code/
Code node documentation | n8n Docs
Integrations Built-in nodes Core nodes Code code code node Code node Use the Code node to write custom JavaScript or Python and run it as a step in your workflow. Examples and templates For usage examples and templates to help you get started, refer to n8n
docs.n8n.io
3) Loop Over Items 노드 (순차 실행)
이 노드는 Code 노드에서 받은 여러 개의 아이템(기사)을 하나씩 순서대로 다음 노드(HTTP Request)로 보내주는 역할을 해요.
| 설정 항목 | 값 | 설명 |
|---|---|---|
| Operation Mode | Loop Over Items | 아이템을 하나씩 순회해요. |
| Batch Size | 1 | 한 번에 1개의 아이템만 처리하도록 설정돼요. |
https://docs.n8n.io/integrations/builtin/core-nodes/n8n-nodes-base.splitinbatches/
Loop Over Items (Split in Batches) | n8n Docs
Integrations Built-in nodes Core nodes Loop Over Items The Loop Over Items node helps you loop through data when needed. The node saves the original incoming data, and with each iteration, returns a predefined amount of data through the loop output. When t
docs.n8n.io
4) HTTP Request 노드 - FastAPI 호출
'Loop Over Items' 노드에서 하나씩 넘어온 아이템을 FastAPI 서버로 전송해요.
| 설정 항목 | 값 | 설명 (초보자용) |
|---|---|---|
| Method | POST | FastAPI에서 @app.post로 만들었기 때문에 POST로 보내요. |
| URL | http://fastapi:8000/scrape |
[중요] localhost가 아닌 fastapi:8000을 사용하고 있네요. 이 의미는 "N8N도 Docker 컨테이너로 실행 중이고, fastapi라는 서비스 이름으로 API 서버에 접속한다"는 뜻이에요. 만약 같은 Docker 네트워크에 속해있지 않다면 통신되지 않으니 그럴 경우 localhost로 바꿔주세요. |
| Body Content Type | JSON | JSON 형식으로 데이터를 전송해요. |
| JSON/RAW Parameters | ={{ $json.scrapeRequest }} |
[핵심] N8N 표현식이에요. "이전 노드에서 받은 데이터($json)의 scrapeRequest 객체를 통째로 Body에 넣어라"는 의미예요. |
https://docs.n8n.io/integrations/builtin/core-nodes/n8n-nodes-base.httprequest/
HTTP Request node documentation | n8n Docs
Integrations Built-in nodes Core nodes HTTP Request HTTP Request node The HTTP Request node is one of the most versatile nodes in n8n. It allows you to make HTTP requests to query data from any app or service with a REST API. You can use the HTTP Request n
docs.n8n.io
5) WebpageContentExtractor 노드 (본문 추출)
N8N 기본 노드가 아닌 커뮤니티 노드예요. 이전에 제가 작성했던 글 참고해 주세요.
| 설정 항목 | 값 | 설명 |
|---|---|---|
| Source | HTML | 이전 'HTTP Request' 노드에서 받은 HTML 데이터를 입력으로 사용해요. |
| HTML | ={{ $json.html }} |
FastAPI 응답($json)에서 html 키의 값을 가져와요. |
| Extraction Values | (기본값) | 이 노드가 알아서 HTML에서 '본문 텍스트(text)'와 '제목(title)' 등을 추출해 줘요. |
이 노드가 실행된 후, 워크플로우는 다시 'Loop Over Items' 노드로 돌아가서 다음 아이템을 처리해요.
https://community.n8n.io/t/custom-node-webpage-content-extractor/34942
Custom node: Webpage content extractor
Hi everyone! I want to share a custom node I just built: Webpage Content Extractor. https://github.com/Savjee/n8n-nodes-webpage-content-extractor It takes a HTML document as input and extracts the main contents from it. Sidebars, headers, and footers are a
community.n8n.io
6) N8N에서 워크플로우 실행
FastAPI 서버가 켜진 것을 확인했다면, N8N 워크플로우를 활성화(Active)하거나 "Execute Workflow" 버튼을 클릭해 수동으로 테스트해요. 'Loop Over Items' 노드가 아이템을 하나씩 순회하며 'HTTP Request' 노드를 실행하는 것을 볼 수 있을 거예요.
실행이 완료되면 Loop Over Items의 Done에 연결된 'Convert to File'에서 다음 엑셀 파일을 받아볼 수 있어요.

트러블슈팅 (Q&A)
FastAPI가 503 Service Unavailable 오류를 반환해요.
증상: /scrape 호출 시 "브라우저가 연결되지 않았어요"라는 503 오류가 발생해요.
원인: FastAPI 서버는 켜졌지만, lifespan
해결:
- 확인 1: docker ps 명령어로 playwright 컨테이너가 'Up' 상태인지 확인해요.
- 확인 2: docker compose logs fastapi 로그를 확인해서 ❌ Playwright 연결 실패: 오류 메시지가 있는지 확인해요.
- 확인 3: docker-compose.yml의 PLAYWRIGHT_SERVER_URL이 ws://playwright:3000으로 올바르게 설정되었는지 확인해요.
"Browser closed unexpectedly" (FastAPI 오류)
증상: Playwright의 브라우저가 크롤링 도중 예고 없이 종료됐어요.
원인: playwright-server 컨테이너의 메모리(특히 공유 메모리)가 부족해요.
해결:
- docker-compose.yml의 playwright 서비스에 shm_size: 2gb (또는 4gb) 설정을 추가하거나 늘려주세요.
"Connection refused" (N8N 오류)
증상: N8N의 'HTTP Request' 노드가 FastAPI 서버에 접근할 수 없어요.
원인: N8N이 FastAPI 서버의 주소를 잘못 알고 있어요.
해결:
- 시나리오 1 (N8N이 PC에 설치된 경우): N8N의 'HTTP Request' 노드 URL은 http://localhost:8000/scrape가 맞아요. docker compose ps로 fastapi가 0.0.0.0:8000 포트에 잘 연결되어 있는지 확인해요.
- 시나리오 2 (N8N이 Docker로 실행 중인 경우): N8N 컨테이너가 fastapi-server와 동일한 Docker 네트워크(이 글에서는 app-network)에 연결되어 있어야만 해요.
- 시나리오 3(N8N이 다른 PC에 설치된 경우): fastAPI를 동작시키고 있는 서버의 <IP 주소>:8000 으로 변경해주세요. 만약 중간에 방화벽등이 있을경우 허용되어있는지 확인해요.
HTML이 비어있거나 불완전한 경우 (크롤링 성공)
증상: 크롤링은 성공(success: true)했으나 WebpageContentExtractor 노드가 본문을 추출하지 못해요.
원인: JavaScript 렌더링이 완료되기 전에 Playwright가 HTML을 가져왔어요. N8N 코드에서 wait_for: "load"를 사용하셔서 그럴 수 있어요.
해결:
- 해결책 1 (권장): N8N의 'Code' 노드에서 wait_for: "load"를 "networkidle"로 변경해 보세요. JS 로딩을 더 확실히 기다려줘요.
- 해결책 2 (특정 요소 대기): main.py의 page.goto(...) 다음에, 그 페이지에서 '반드시' 로드되어야 하는 요소(예: 기사 본문 컨테이너)를 기다리는 코드를 추가해요.
# page.goto(...) 다음에 추가 # (예시) 기사 본문 선택자 await page.wait_for_selector("#news_end_content", timeout=10000) html_content = await page.content() # 그 후에 HTML을 가져옴
정리
N8N과 Playwright를 연동해서 웹 데이터를 스크래핑하는 글을 작성해 봤어요.
모든 서비스들을 Docker로 올려놨고 같은 네트워크를 사용하도록 설정했기에 각 서비스 간 통신을 쉽게 설정할 수 있었어요.
N8N과 FastAPI, Playwright를 통해 웹 스크래핑 기능을 만들었지만 몇 가지 기능이 제외된 상태예요.
- FastAPI 사용 시 인증 부재
인증 없이 요청만 보내면 누구든 사용할 수 있어요. 인증 또는 JWT를 사용하도록 수정한다면 보안을 더 강화할 수 있어요.
해당 포트에 대한 접근 제한(방화벽 등)을 걸어서 보안을 강화할 수 있지만 인증 로직을 넣는 게 안전해요. - 병렬 동작 부재
지금은 한 번에 1개의 URL만 스크래핑해요. 그래서 수십, 수백 개의 사이트를 크롤링하려면 많은 시간이 소요될 수 있어요.
이를 방지하기 위해 병렬로 수행할 수 있도록 기능을 추가하면 좋아요. - 중복 제거
지금은 단순히 웹만 스크래핑하는 거라 동일한 URL을 몇 번이고 스크래핑할 수 있어요.
그래서 기존 스크래핑 했던 이력을 저장하여 중복 방지 기능을 추가하면 좋아요.
이외에도 많은 기능이 부족하지만, 단순히 스크래핑 기능을 구현하는 데는 쉽게 따라올 수 있을 것 같아요.
다음에는 Google Sheet와 연동해서 데이터를 저장하는 글을 써보도록 할게요.
'N8N' 카테고리의 다른 글
| N8N - 웹 스크래핑 자동화: JWT 인증 + 병렬 처리 + PostgreSQL 중복 방지 (0) | 2025.11.19 |
|---|---|
| N8N - 웹 스크래핑 데이터 Google Sheet 저장 (0) | 2025.11.15 |
| N8N 사용법 - RSS 피드 본문 추출 후 엑셀 저장하기 (0) | 2025.09.18 |
| N8N Guide - 커뮤니티 노드(Community Node) 설치 (0) | 2025.09.10 |
| N8N 사용법 - HTTP Request 노드 및 HTTP 메소드 이해 (0) | 2025.09.08 |



