
Playwright는 Microsoft가 개발한 오픈소스 브라우저 자동화 및 테스트 프레임워크예요. Chromium, Firefox, WebKit 등 여러 브라우저를 지원하며, 하나의 API로 크로스 브라우저 테스팅을 수행할 수 있어요. 특히 자동 대기(auto-wait) 기능을 통해 셀레니움(Selenium)의 단점을 해결한 강력한 도구예요.
📑 목차
개요: Playwright란?
Playwright는 Microsoft에서 개발한 오픈소스 브라우저 자동화 및 테스트 프레임워크로 코드를 통해 웹 브라우저(Chrome, Firefox 등)를 제어할 수 있게 해줘요. 웹 페이지 열기, 버튼 클릭, 폼 입력, 스크린샷, 데이터 추출 등 브라우저에서 사람이 할 수 있는 거의 모든 작업을 코드로 자동화할 수 있어요.
설치와 준비: 2단계 설치 (필수)
Playwright를 로컬에서 사용하려면 2가지 파일을 설치해야해요.
- Python 라이브러리(제어 명령어) 설치
- 실제 브라우저(제어 대상) 설치예요.
PIP를 통한 설치
Python PIP가 설치된 환경에서 아래 명령어로 Playwright를 설치할 수 있어요.
# 1단계: Playwright Python 라이브러리 설치
pip install playwright
# 2단계: Playwright가 제어할 실제 브라우저(Chromium 등) 설치
playwright installpip install playwright: Python 코드에서import playwright를 사용하기 위한 'Python 패키지'를 설치해요. 여기에는.launch(),.goto()같은 모든 제어 **명령어**가 들어있어요.playwright install: 위에서 설치한 Python 명령어로 제어할 '실제 브라우저(Chromium, Firefox, WebKit) 프로그램'을 다운로드해요. 이 브라우저들은 Playwright에 맞게 최적화되어 있어요.
중요: 1단계만 설치하면 "브라우저 실행 파일을 찾을 수 없습니다" (Browser not found) 오류가 발생해요. 반드시 2단계 playwright install까지 실행해야 해요.
PIXI를 통한 설치
저는 Pixi를 사용하고 있어요. 이건 차세대 Python 패키지 관리 도구로 Conda와 유사하지만 더 가볍고 빠른 특징을 가지고 있어요.
나중에 이에 대한 해포스팅을 해보도록 할게요. 우선 Pixi를 통해 설치할 때는 아래 방법으로 설치할 수 있어요.
# 1단계: Pixi를 통한 Playwright Python 라이브러리 설치
pixi add --pypi playwright
# 2단계: Playwright가 제어할 실제 브라우저(Chromium 등) 설치
playwright install설치 확인
설치가 완료되었으면, playwright가 잘 동작하는지 확인해 볼게요. 아래 명령어를 통해 Playwright 브라우저로 네이버에 접속할게요.
playwright open naver.com위 명령어로 브라우저가 실행되면 아래와 같은 화면이 나타나요.
Chromium이 실행된 것을 볼 수 있어요. 이러면 정상적으로 설치된 거예요.

Playwright 코드의 3단계 기본 구조
본글에 있는 모든 Playwright 코드는 아래 3가지 핵심 객체를 중심으로 동작해요.
| 단계 | 객체 (변수명 예시) | 설명 (비유) |
|---|---|---|
| 1단계: 프레임워크 시작 | p (Playwright) |
Playwright라는 '프로그램 자체'를 시작/종료해요. (자동차 시동 켜기) |
| 2단계: 브라우저 실행 | browser (Browser) |
실제 웹 브라우저 프로그램(Chrome 등)을 메모리에 띄워요. (자동차 운전석 탑승) |
| 3단계: 페이지 작업 | page (Page) |
브라우저 안의 '새로운 탭(Tab)'을 의미해요. [중요] 모든 실제 웹 조작(클릭, 이동 등)은 이 page 객체를 통해 이루어져요. (네비게이션 조작) |
동기 (Sync) API: 기본 틀 및 필수 옵션 상세 설명
가장 기본이 되는 사용법은 동기식 함수를 사용해서 코드를 만드는 거예요. 동기식 함수는 sync_playwright를 통해 사용할 수 있어요.
'with' 구문: 안전한 실행을 위한 기본 틀
Playwright 코드를 실행할 때는 with sync_playwright() as p: 구문을 사용하는 것이 좋아요.
'with' 구문(Context Manager)이란?
with 문은 Python에서 기본적으로 제공하는 문법으로 컨텍스트 매니저(Context Manager) 라는 객체를 사용해서 리소스를 열고 → 사용하고 → 정리하는 단계를 자동으로 처리하는 기능을 제공해요. 그래서 이 문법을 이용해서 Playwright를 사용하면 코드가 예기치 못하게 종료되거나 오류가 발생하더라도 Playwright와 브라우저를 안전하게 종료해 주는 역할을 수행할 수 있어요.
이렇게 코드를 짜는 이유는 프로그램이 비정상 종료될 때마다 눈에 보이지 않는 브라우저 프로세스가 계속 쌓여 컴퓨터가 느려질 수 있어요. with 구문은 이러한 프로세스를 자동으로 종료시켜 줘요.
기본 코드 구조
코드에 대한 설명은 코드 내 포함된 주석을 참고해 주세요.
# 1. 'sync_api'에서 'sync_playwright'라는 함수를 가져와요.
from playwright.sync_api import sync_playwright
def run_sync():
# 2. 'with' 구문으로 Playwright를 안전하게 시작해요.
# Playwright 객체를 'p'라는 변수로 받아요. (1단계: 시동 켜기)
with sync_playwright() as p:
# 3. 'p' 객체를 통해 사용할 브라우저(chromium)를 선택하고,
# .launch() 메서드로 브라우저를 실행해요. (2단계: 운전석 탑승)
browser = p.chromium.launch(
headless=False, # [필수] False로 설정해야 브라우저 창이 눈에 보여요.
slow_mo=500 # [선택] 각 동작(클릭 등) 사이에 500ms(0.5초) 딜레이를 줘요.
# 자동화가 너무 빨라 눈으로 확인하기 어려울 때 유용해요.
)
# 4. 실행된 브라우저(browser)에서 .new_page()로 새 탭을 열어요.
# 이 'page' 객체로 모든 것을 제어해요. (3단계: 네비게이션 조작)
page = browser.new_page()
# 5. page 객체의 .goto() 메서드로 원하는 URL로 이동해요.
page.goto("https://www.naver.com")
# 6. 페이지 제목을 가져와 출력해요.
print(f"현재 페이지 제목: {page.title()}")
# 7. (선택) 브라우저를 명시적으로 닫아요.
# (사실 'with' 구문이 끝나면 자동으로 닫혀요.)
browser.close()
# Python 스크립트를 직접 실행할 때 run_sync() 함수를 호출해요.
if __name__ == '__main__':
run_sync()네이버에 접속한 뒤 페이지 제목을 출력하는 코드예요. 실제 코드를 실행 한 화면을 보면 아래와 같아요.
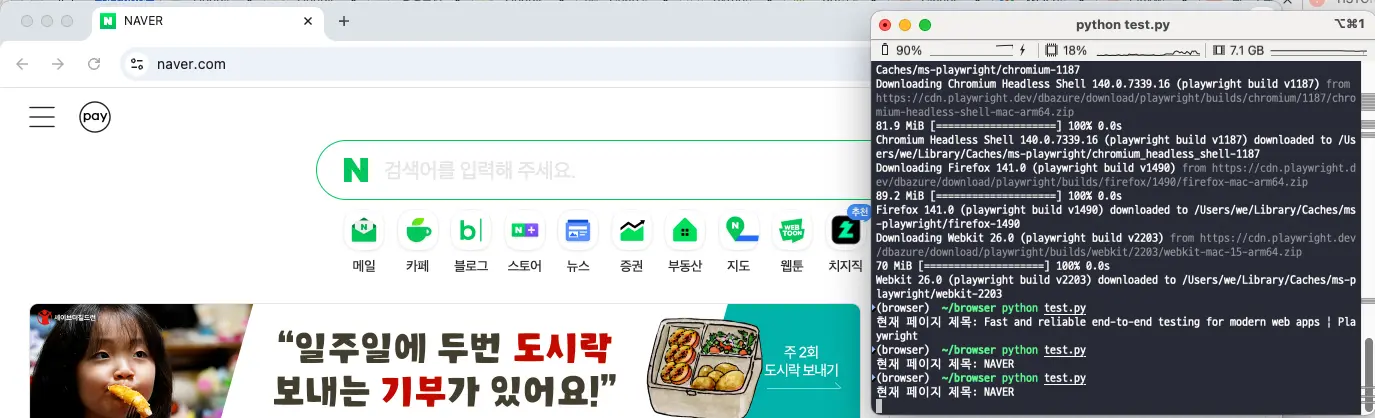
자주 사용하는 Launch 옵션
.launch() 메서드 안에는 여러 옵션을 넣어 브라우저의 상태를 제어할 수 있어요.
headless=False: (기본값 `True`) 초보자 필수 옵션. `False`로 설정해야 브라우저 창이 눈에 보이게 실행돼요. `True`인 경우 백그라운드에서만 실행돼요. `False` 설정 후, 브라우저가 내가 의도한 대로 동작하는지 확인할 수 있어요.slow_mo=500: 각 Playwright 명령 사이에 500ms (0.5초)의 지연 시간을 줘요. 자동화가 너무 빨라 사람이 확인하기 어려울 때 유용해요.args=["--start-maximized"]: (Chromium 계열) 브라우저를 **최대화**된 상태로 시작하게 해요.channel="chrome": (고급) `playwright install`로 설치한 Chromium 대신, 내 PC에 이미 설치된 **Chrome 브라우저**를 사용하도록 지정해요. (단, Playwright 버전과 호환성이 맞아야 해요.)
비동기 (Async) API: (고급) 병렬 작업용
(초보자는 이 섹션을 건너뛰어도 좋아요.)
대규모 크롤링 등 **여러 작업을 동시에 처리**할 때 사용해요. async_playwright를 사용하며, 코드 앞에 async, await 키워드가 붙어요. 사실 아래와 같이 하나의 사이트로 동작하는 코드의 경우는 차이가 없어요.
하지만 10개의 사이트를 탐색해야 하는 경우, 동기식 sync_api의 경우 10개의 사이트를 순차적으로 탐색해야 해요.
하지만 비동기식 async_api의 경우 10개의 사이트를 동시에 탐색해서 결과를 가져올 수 있으니 속도면에서 훨씬 빠르죠.
대신 좀 더 Python 코드를 전문적으로 다뤄야지 활용할 수 있어요.
import asyncio
from playwright.async_api import async_playwright
async def run_async():
# 'async with'를 사용하여 비동기적으로 Playwright를 관리해요.
async with async_playwright() as p:
# 모든 Playwright 명령에 await를 사용해요.
browser = await p.firefox.launch(headless=True)
page = await browser.new_page()
await page.goto("https://www.naver.com")
print(f"페이지 제목: {await page.title()}")
await browser.close()
if __name__ == '__main__':
# 비동기 함수를 실행하려면 asyncio.run()이 필요해요.
asyncio.run(run_async())
위 코드를 실행하면 아래와 같은 결과를 볼 수 있어요. fierfox 브라우저가 사용되도록 코드가 구성되어 있어요.

핵심 사용법
요소 조작 (Locator) 및 상세 설명
Playwright는 웹 요소를 찾을 때 **Locator API**를 사용하는 것을 강력히 권장해요.
왜 Locator를 써야 하나요?
Selenium 등 구형 도구는 find_element_by_id("login-button")처럼 HTML의 ID나 CSS 클래스에 의존했어요. 하지만 웹사이트 디자인이 바뀌면 이 ID가 깨져서 자동화 코드가 멈췄어요.
Playwright의 Locator (get_by_role("button", name="로그인"))는 '역할'과 '이름'으로 요소를 찾아요. 이는 "사용자가 '로그인'이라고 쓰인 '버튼'을 누른다"는 행동과 같아요. 웹사이트의 내부 ID가 바뀌어도, 사용자가 보는 '로그인 버튼'이 그대로 있다면 코드는 깨지지 않고 동작해요.
| Locator 메서드 | 찾는 방법 | 예시 (상황) |
|---|---|---|
page.get_by_text() |
요소 내부의 텍스트로 찾기 | page.get_by_text("회원가입") (회원가입 텍스트) |
page.get_by_role() |
버튼, 텍스트박스 등 역할(Role)로 찾기 | page.get_by_role("button", name="검색") (이름이 '검색'인 버튼) |
page.get_by_label() |
Label 텍스트로 연결된 입력 필드 찾기 | page.get_by_label("비밀번호") ('비밀번호' 라벨이 붙은 입력창) |
page.locator() |
CSS 선택자나 XPath로 찾기 (고급) | page.locator("div.header") (header 클래스를 가진 div) |
import time
from playwright.sync_api import sync_playwright
def run_sync():
with sync_playwright() as p:
browser = p.chromium.launch(
headless=False,
slow_mo=500
)
page = browser.new_page()
page.goto("https://www.naver.com")
print(f"현재 페이지 제목: {page.title()}")
# 1. Locator를 사용해 요소를 찾아요. (이때 바로 실행되지 않음)
# '로그인'이라는 이름(텍스트)을 가진 '버튼' 역할을 찾아요.
submit_button = page.get_by_role("link", name="NAVER 로그인")
submit_button.click() # 버튼을 클릭해요.
# 2. 찾은 요소에 실제 행동(.fill, .click)을 명령해요.
# 이때 Playwright가 해당 요소가 나타날 때까지 자동으로 기다려요.
# '아이디'라는 라벨이 붙은 입력창을 찾아요.
username_input = page.get_by_label("아이디 또는 전화번호")
username_input.fill("knockknows") # 값을 입력해요.
password_input = page.get_by_label("비밀번호")
password_input.fill("knockknows") # 값을 입력해요.
time.sleep(5) # 5초 대기 후 종료
# Python 스크립트를 직접 실행할 때 run_sync() 함수를 호출해요.
if __name__ == '__main__':
run_sync()
기존 동기화 코드에서 Locator를 테스트할 수 있는 코드를 추가한 코드예요. 위 코드를 사용하면 네이버에 접속 후 로그인 버튼을 누른 뒤 ID/PW를 입력해요.
자주 사용하는 Locator 액션
| 액션 | 설명 | 예시 |
|---|---|---|
.click() |
요소를 클릭해요 | page.get_by_role("button").click() |
.fill() |
입력 필드에 값을 입력해요 | page.get_by_label("이메일").fill("test@example.com") |
.pressSequentially() |
키보드 입력을 시뮬레이션 (한 글자씩 입력) | page.get_by_label("검색").pressSequentially("playwright") |
.check() |
체크박스를 체크해요 | page.get_by_label("약관 동의").check() |
.selectOption() |
드롭다운에서 옵션을 선택해요 | page.locator("select").selectOption("value") |
.hover() |
요소 위에 마우스를 올려요 | page.get_by_text("메뉴").hover() |
스크린샷 저장
page.screenshot() 메서드를 이용해 페이지 전체나 특정 요소의 스크린샷을 저장할 수 있어요.
import time
from playwright.sync_api import sync_playwright
def run_sync():
with sync_playwright() as p:
browser = p.chromium.launch(
headless=False,
slow_mo=500
)
page = browser.new_page()
page.goto("https://www.naver.com")
# 1. 전체 페이지 스크린샷 캡처 (스크롤 영역 포함)
# 'path'는 저장할 파일명, 'full_page=True'는 스크롤을 포함한 전체 페이지를 의미해요.
page.screenshot(path="fullpage.png", full_page=True)
# 2. 특정 요소(예: 헤더)를 Locator로 찾은 후 캡처
# 'header'라는 HTML 태그를 찾아요. (CSS 선택자 방식)
header_element = page.get_by_role("banner")
header_element.screenshot(path="header_only.png")
browser.close()
time.sleep(5) # 5초 대기 후 종료
# Python 스크립트를 직접 실행할 때 run_sync() 함수를 호출해요.
if __name__ == '__main__':
run_sync()위 코드는 전체 화면과 헤더 부분만 스크린샷을 찍어서 파일로 저장하는 함수예요. 코드 실행 시 아래와 같은 결과를 볼 수 있어요.


Playwright의 핵심: 자동 대기 (Auto-wait)
Auto-Wait은 Selenium의 가장 큰 고통을 해결한 기능이에요.
Selenium에서는 요소를 클릭하기 전에 time.sleep()이나 WebDriverWait 같은 코드를 넣어 페이지 로딩을 수동으로 기다려야 했어요.
Playwright는 page.click()이나 page.fill() 같은 동작을 수행하기 전에, 해당 요소가 ① DOM에 존재하고, ② 화면에 실제로 나타나며, ③ 클릭 가능한 상태가 될 때까지 **자동으로 기다려줘요**. 개발자가 수동으로 대기 코드를 작성할 필요가 거의 없어 코드가 매우 간결하고 안정적이 돼요.
하지만 가끔은 명시적으로 대기가 필요한 경우도 있어요:
# 1. 특정 요소가 나타날 때까지 대기 (최대 5초)
page.wait_for_selector("div.result", timeout=5000)
# 2. 페이지 로드가 완전히 끝날 때까지 대기
page.wait_for_load_state("networkidle")
# 3. 간단히 특정 시간만큼 대기 (권장하지 않음)
import time
time.sleep(2) # 2초 대기
실전 예제: 네이버 뉴스 제목 가져오기
지금까지 배운 내용을 종합하여 실제로 동작하는 크롤링 예제를 만들어볼게요.
아래는 네이버 뉴스 홈에서 강조 처리된 뉴스 기사들만 가져오는 코드예요.
from playwright.sync_api import sync_playwright
def crawl_naver_news():
with sync_playwright() as p:
# 브라우저 실행 (화면에 보이게)
browser = p.chromium.launch(slow_mo=1000)
page = browser.new_page()
# 네이버 뉴스 페이지로 이동
page.goto("https://news.naver.com")
# 헤드라인 뉴스 제목들을 모두 찾기
all_headlines = page.get_by_role("strong").all()
# class가 "cjs_news_title"인 것만 필터링
filtered_headlines = [
headline for headline in all_headlines
if 'cnf_news_title' in (headline.get_attribute('class') or '')
]
print(f"\n=== 오늘의 주요 뉴스 ({len(filtered_headlines)}개) ===\n")
# 각 제목 출력
for i, headline in enumerate(filtered_headlines, 1):
title = headline.text_content()
print(f"{i}. {title}")
browser.close()
if __name__ == '__main__':
crawl_naver_news()cnf_new_title)가 작동하지 않는다면, 브라우저의 개발자 도구(F12)를 열어 실제 HTML 구조를 확인하고 선택자를 수정해야 해요.
자주 발생하는 오류와 해결 방법 🆕
1. "Executable doesn't exist" 오류
원인: playwright install 명령을 실행하지 않았어요.
해결: 터미널에서 playwright install을 실행하세요.
2. "Timeout" 오류
원인: 요소를 찾을 수 없거나, 페이지 로딩이 너무 오래 걸려서 타임아웃 시간이 초과되었어요.
해결:
- Locator가 정확한지 확인하세요 (개발자 도구로 HTML 구조 확인)
- timeout 옵션을 늘려보세요: page.click("button", timeout=10000)
- 인터넷 연결 상태를 확인하세요
3. "Element is not visible" 오류
원인: 요소가 화면에 보이지 않는 상태예요 (스크롤 필요, 또는 숨겨진 상태).
해결:
- 요소까지 스크롤: element.scroll_into_view_if_needed()
- 팝업이나 광고가 가리고 있는지 확인하세요
4. 한글 입력이 안 되는 경우
원인: 일부 웹사이트는 한글 입력을 특별하게 처리해요.
해결: .fill() 대신 .press_sequentially()를 사용하세요:
page.get_by_label("검색").press_sequentially("한글테스트", delay=100)정리
Playwright에 대해 알아봤어요. Playwright는 로컬에서도 설치 가능하고 코드를 통해 쉽게 컨트로 가능하다는 특징을 가지고 있어요.
이를 통해 사이트에서 자동화를 수행하거나, 크롤링을 수행하는 등의 작업을 수행할 수 있어요.
다음에는 Playwright를 통해 N8N과 연동해서 사용하는 방법에 대해 포스팅해 볼게요.
'기타' 카테고리의 다른 글
| 페이지 동적 렌더링을 위한 브라우저리스(Browserless) (0) | 2025.09.23 |
|---|---|
| 헤츠너(Hetzner) 클라우드 20EUR 크레딧 무료로 받기 (0) | 2025.09.15 |
| JWT(Json Web Token) (1) | 2025.09.06 |
| 파일질라(Filezila) 사용법 (2) | 2025.09.02 |



