
Browserless는 관리형 헤드리스 브라우저(Chrome)를 API로 제공해요. 콘솔·HTTP API·BrowserQL로 스크린샷, PDF, HTML/텍스트 추출을 손쉽게 실행할 수 있어요. 설치/업데이트/버전 호환 같은 번거로운 작업을 대신 처리하므로, 로컬·서버·CI에서 브라우저 환경을 직접 꾸리지 않아도 돼요. 특히 동적 렌더링이 필요한 페이지, SPA, 로그인 이후 화면처럼 정적 요청만으로는 어려운 경우에 쉽게 사용할 수 있으며, 클라우드 버전에는 Free Tier를 제공하기 때문에 사용량이 적은 경우 충분히 활용할 수 있어요
개요
웹 페이지를 웹브라우저가 아닌 Curl이나 기타 도구로 탐색하다 보면 많은 사이트들이 동적 렌더링 방식으로 콘텐츠를 제공해요.
우리가 일반적으로 사용하는 브라우저는 웹 페이지 접속 시 자동으로 자바스크립트를 실행하며
콘텐츠를 보여주는 동적 렌더링을 제공해요.
하지만 Curl이나 일반적으로 웹 사이트 콘텐츠를 가져오려는 도구들은 동적 렌더링을 제공하지 않기 때문에
내가 웹 브라우저에서 보던 것과 다른 결과물을 가져오는 경우가 많아요.
그래서 이 부분을 해결하기 위해 여러 도구를 찾았어요.
처음에는 이전에 사용해 본 셀레니움(Selenium)을 사용할지, 아니면 MS에서 나온 Playwright을 사용할지 고민했어요.
하지만 브라우저를 관리해야 한다는 번거로움 때문에 찾다가 브라우저리스(Browserless)라는 도구를 발견했어요.
이 도구는 셀프 호스팅도 제공하지만, 클라우드에서 Free Tier를 제공하기에 사용해보려고 해요.
Browerless의 특장점
브라우저가 필요한 업무는 늘어났지만, 서버나 CI에 브라우저를 설치·유지하는 일은 만만하지 않아요.
Browserless는 이런 환경적 부담을 줄이고 안정적으로 동적 페이지를 자동화할 수 있게 도와줘요.
- 동적 렌더링이 필수인 SPA/Infinite Scroll/클라이언트 렌더링 페이지를 처리하기 좋아요.
- 로그인 이후 대시보드·내 정보·검색 결과처럼 쿠키/세션이 필요한 화면을 자동화하기 쉬워요.
- 설치·업데이트 부담이 없고 크롬/드라이버 버전 호환 문제를 피할 수 있어요.
- 서버리스·CI처럼 실행 환경이 제한적인 곳에서도 동일한 방식으로 동작해요.
- 타 도구와 비교했을 때 관리가 필요하지 않기에 손쉽게 사용할 수 있어요(클라우드 기준)
웹 콘솔에서 BrowserQL을 이용해 브라우저를 바로 제어할 수 있어요.
복잡한 SDK 세팅 없이 쿼리를 실행하고 결과를 받아보는 데 최적이에요.
아래 예시를 그대로 복사해 실행하면, 스크린샷·PDF·텍스트·HTML을 순식간에 얻을 수 있어요.
Browerless 가입 및 인터페이스
Browerless 가입 링크
브라우저리스는 아래 링크를 통해 가입할 수 있어요
구글 계정을 가지고 있다면 쉽게 가입할 수 있기에 따로 가입 절차는 적지 않을게요.
https://account.browserless.io/signup/email/?plan=free
https://account.browserless.io/signup/email/?plan=free
account.browserless.io
Browerless 인터페이스
브라우저리스 Home
브라우저리스에 가입 또는 로그인했다면 아래 웹 콘솔이 보여요.
Home 메뉴로 중앙의 퀵 메뉴들을 통해 원하는 기능을 수행하는 페이지로 이동할 수 있어요.

브라우저리스 Dashboard
좌측 메뉴바에서 [ Dashboard ]를 선택해서 이동해요.
대시보드에서는 진행한 작업들의 통계와 현재 사용량을 볼 수 있어요.

하단에는 현재 계정에서 구독 사용량을 볼 수 있어요.
Free Tier 계정에는 1000 Unit이 제공돼요.
1 Unit 당 30초 동안 브라우저를 제어할 수 있어요.
브라우저리스 BrowserQL Editor
다음으로 핵심기능인 BrowserQL Editor 메뉴예요.
여기서는 실제 브라우저리스 기능을 사용해 볼 수 있어요.
좌측 화면에 있는 BrowserQL 문법으로 코드를 작성하고, 중앙의 Play 버튼을 누르면 우측 화면에서
원격 브라우저가 구동되며 코드로 정해진 작업을 수행해요.
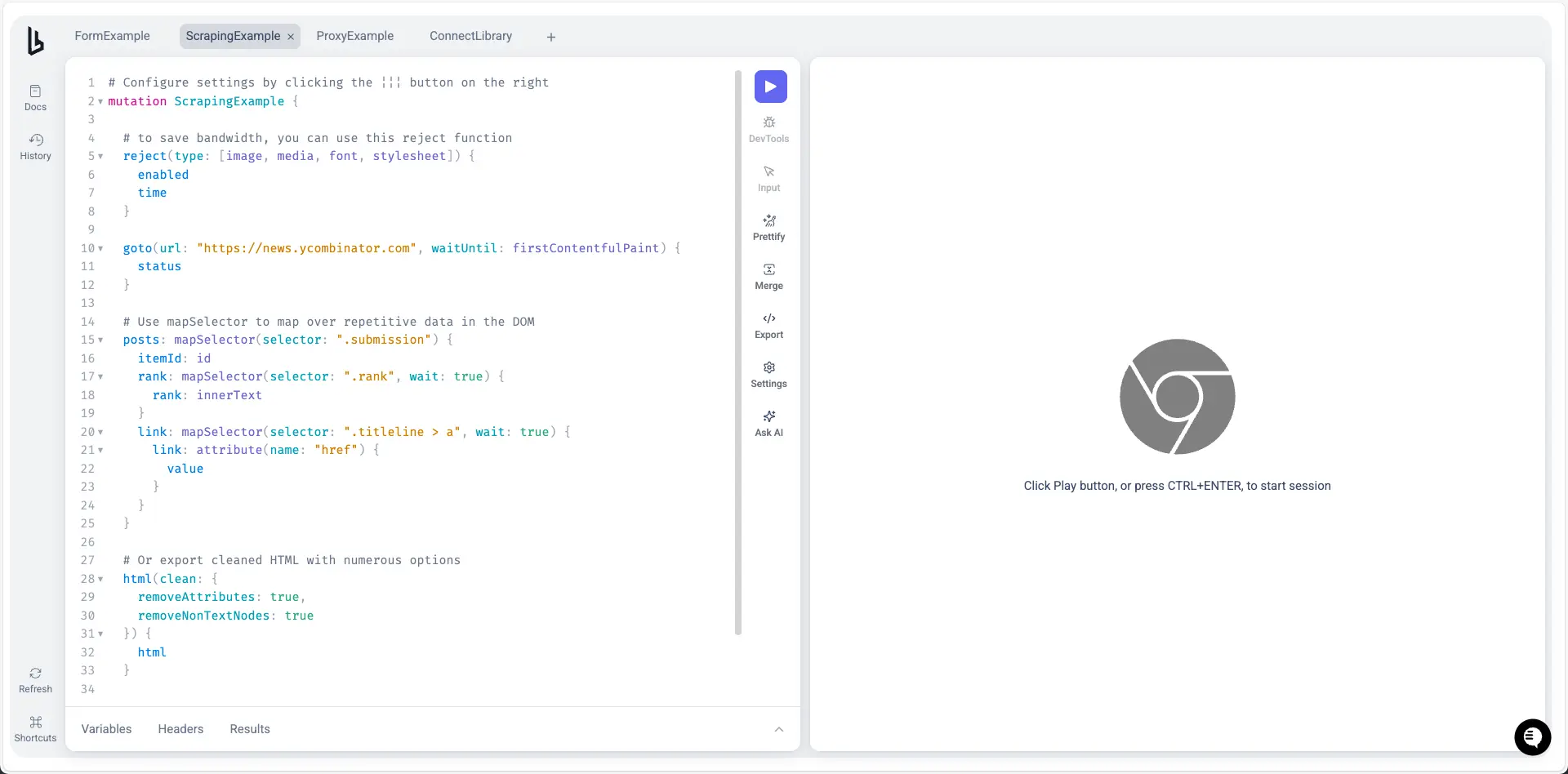
이 외 여러 가지 메뉴들이 있지만 상기 3개의 메뉴만 주로 사용할 것 같아서 다른 메뉴들은 이번 글에 포함하지 않을게요.
다른 메뉴들에 대한 정보가 필요한 분들은 브라우저리스 콘솔에 가입하셔서 확인하실 수 있어요.
BrowserQL 빠른 이해
BrowserQL은 GraphQL 문법을 차용해 브라우저 동작을 선언적으로 작성해요.
콘솔 편집기에 입력하고 실행하면, 서버가 브라우저를 구동하고 응답 데이터를 반환해요.
기본 쿼리
mutation clean_example {
goto(url: "https://news.jtbc.co.kr/article/NB12263862") {
status
}
html(clean: {
removeAttributes: true,
removeNonTextNodes: true
}) {
html
}
}지정된 URL의 페이지를 열고 HTML을 반환해요.
HTML은 불필요한 스타일이나 기타 광고 등을 제거한 데이터를 반환하는 코드예요.


쿼리 설명
1. mutation clean_example
브라우저리스의 BrowseQL은 GraphQL을 사용해요.
GraphQL에서는 query와 mutation이 있어요.
- query는 단순히 데이터를 읽어오는 작업,
- mutation은 특정 동작을 실행하거나 상태를 바꾸는 작업에 사용됩니다.
여기서는 clean_example이라는 이름의 mutation을 정의해, 페이지 탐색과 HTML 추출이라는 작업을 수행해요.
그래서 mutation 뒤에 오는 이름은 우리가 직접 정의할 수 있고, 작업의 단위로 볼 수 있어요.
2. goto(url: "...")
goto는 지정된 URL로 접속하는 기능이에요.
- 지정한 URL로 브라우저 세션을 이동시켜요.
- status 값을 요청하여 해당 페이지의 HTTP 응답 코드(200, 404 등)를 확인할 수 있어요.
예를 들어 정상적으로 열렸다면 status: 200이 반환돼요.
3. html(clean: {...})
페이지의 HTML을 가져오는 단계로 여기서는 clean 옵션이 적용되어 있어요.
- removeAttributes: true → 모든 태그의 id, class, style 등의 속성을 제거해요.
- removeNonTextNodes: true → <script>, <style>, <img> 같은 텍스트가 아닌 노드를 제거해요.
즉, 광고나 불필요한 태그를 모두 걸러내고 아래와 같이 순수한 텍스트 중심의 HTML만 남게 돼요.

추가 BrowserQL 예시
1) PDF 생성
아래는 지정한 페이지를 PDF로 저장하고 파일 이름과 데이터(Base64)를 받아요.
FCP(FirstContentfulPaint)를 사용하여 콘텐츠가 렌더링 되었을 때 PDF를 생성해요.
- FCP는 사용자가 페이지를 열었을 때, 브라우저가 처음으로 “실제 콘텐츠”를 화면에 그려주는 순간을 말해요.
- 여기서 "콘텐츠"란 텍스트, 이미지, SVG 등 의미 있는 요소예요.
- 단순히 배경색이나 빈 캔버스는 FCP에 포함되지 않음.
즉, FCP가 발생하는 순간은 "페이지가 뜨고 있구나” 하고 사용자가 체감할 수 있는 첫 신호라고 볼 수 있어요.
mutation PDF {
goto(url: "https://example.com",waitUntil: firstContentfulPaint) {
status
}
pdf(displayHeaderFooter: true, printBackground: false, format: a0) {
base64
}
}
2) 페이지 버튼 선택
특정 사이트에서는 접속 시 팝업이 나타나고, 팝업을 해결하기 전까지 페이지가 렌더링 되지 않던지 등 콘텐츠를 보기 어려운 경우가 있어요.
셀리니움이나 기타 다른 브라우저 자동화 도구와 동일하게 브라우저 리스에서도 해당 기능을 수행할 수 있어요.
아래는 CNN에서 팝업을 처리하고 HTML을 추출하는 예제예요.
mutation cnn_news_scraping {
goto(
url: "https://edition.cnn.com/2025/09/22/health/trump-autism-announcement-cause-tylenol"
,waitUntil: firstContentfulPaint) {
status
}
click(
selector: "a[href='#'][style*='background-color: rgb(12, 12, 12)'][style*='height: 48px'][style*='border-radius: 8px']"
visible: true
timeout: 10000
) {
x
y
time
}
waitForSelector(
selector: "[data-editable='headlineText']"
timeout: 30000
visible: true
) {
selector
time
}
html {
html
}
}
3) Cloudflare Capcha 처리
Cloudflare로 봇을 막기 위한 Capcha를 통과할 수 있어요.
아래는 Cloudflare Capcha 테스트 페이지에서 처리하는 쿼리예요.
mutation Verify {
# Enable residential proxies so cloudflare can be solved successfully
goto(url: "https://2captcha.com/demo/cloudflare-turnstile") {
status
}
verify(type: cloudflare) {
found
solved
time
}
}
정리
BrowserQL은 콘솔에서 곧바로 실행 가능한 강력한 인터페이스예요.
PDF 생성, 텍스트·HTML 추출, CAPCHA 우회까지 몇 줄로 구현할 수 있어요.
무료 쿼터를 아껴 쓰며 실험하면, 클라우드 자동화를 안전하고 빠르게 검증할 수 있어요.
'기타' 카테고리의 다른 글
| 브라우저 자동화 도구 Playwright (1) | 2025.11.07 |
|---|---|
| 헤츠너(Hetzner) 클라우드 20EUR 크레딧 무료로 받기 (0) | 2025.09.15 |
| JWT(Json Web Token) (1) | 2025.09.06 |
| 파일질라(Filezila) 사용법 (2) | 2025.09.02 |



